

参考:
- https://blog.csdn.net/zerfew/article/details/116058707
- https://blog.csdn.net/u011017694/article/details/125668869
仓库:https://github.com/libopencm3/libopencm3
虽然说STM32官方已经提供了相当丰富的库与各种组件,但“多个朋友多条路”嘛,多掌握一些知识不是什么坏事;
libopencm3 作为一款完全开源的 ARM Cortex-M 系列微控制器驱动库,以其简洁、轻量和高度模块化的设计,赢得了众多开发者的青睐;
libopencm3 支持包括 ST、Ti、NXP 以及 Freescale 在内的多家芯片厂商,提供统一且贴近硬件的接口,极大地方便了跨平台开发和代码复用;其设计理念强调对硬件寄存器的直接操作,既保留了硬件细节的可控性,也保持了 API 的易用性;
值得一提的是,国产 GD32 MCU 厂商也借鉴了 libopencm3 的设计风格,打造了自家全新的代码库,充分体现了 libopencm3 在嵌入式领域的影响力和实用价值;
接下来的笔记将分享我基于 libopencm3 在 STM32 上的开发体验,涵盖环境搭建、实用示例和调试心得,助力大家更高效地利用这款优秀的开源驱动库;
开发准备
安装交叉编译工具链
首先要确保安装了交叉编译工具链 arm-none-eabi-gcc,这是编译 ARM Cortex-M 系列芯片不可缺少的工具;可以从 ARM 官方网站下载,关键词搜索“arm toolchain”即可找到对应版本;安装完成后,可以通过以下命令验证:
1 | arm-none-eabi-gcc --version |
获取 libopencm3 库
从官方仓库下载最新的 libopencm3 代码,建议将其完整复制到你的工作目录中;这个库会作为所有基于 libopencm3 的项目的公共依赖使用,保持独立和统一管理有助于后续维护;
获取 libopencm3 代码后,还需要先对其进行编译,以便生成可用的文件;在 libopencm3 目录下执行以下命令:
1 | make -j$(nproc) |
创建项目目录结构
在与 libopencm3 同级的位置,创建一个新的文件夹用于存放你的工程代码;典型结构如下:
1 | project-root/ |
这样做方便将库和项目代码分开管理;
获取示例工程配置
可以从 ibopencm3 的 examples 仓库下载对应 STM32 型号的示例工程;找到一个适合你的硬件型号的例程,复制里面的 Makefile 和其他相关配置文件到你的项目文件夹MyProject下(与 libopencm3 同级),以此作为起点;
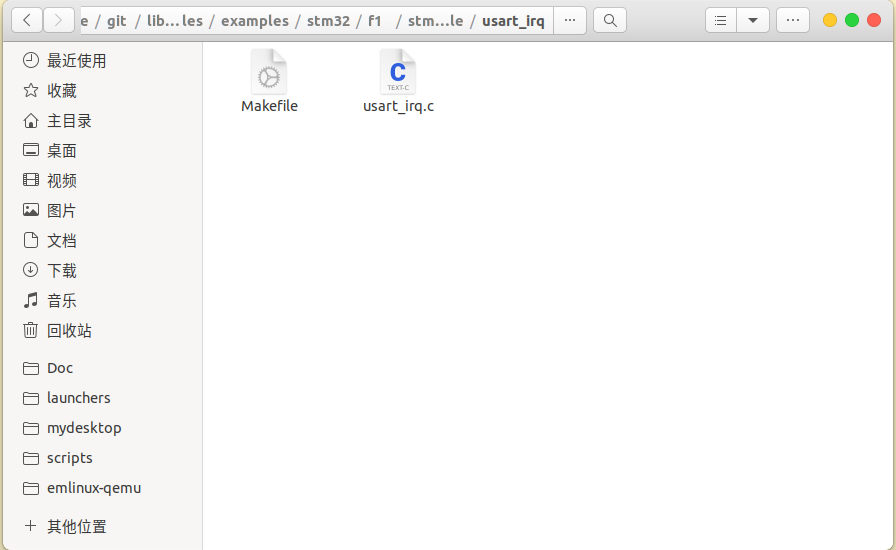
复制必要的配置文件
- 复制示例中的型号相关的Makefile文件到MyProject;
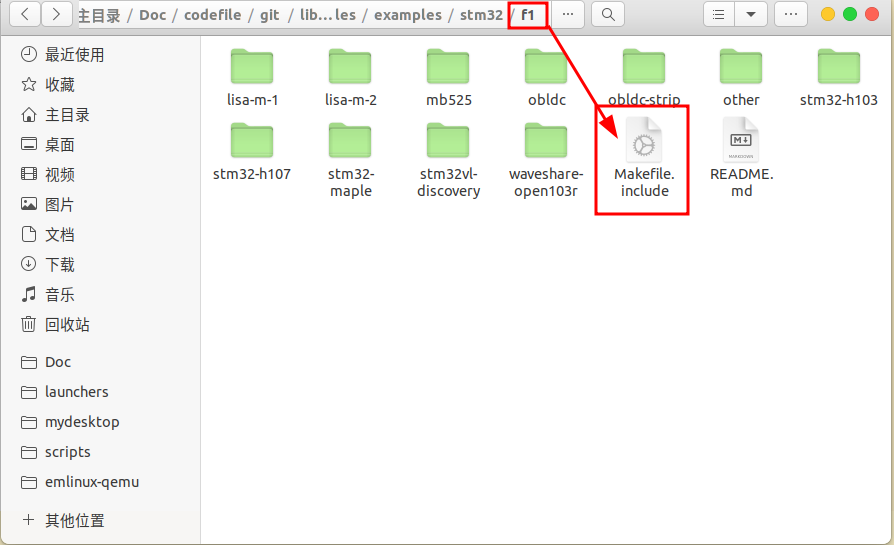
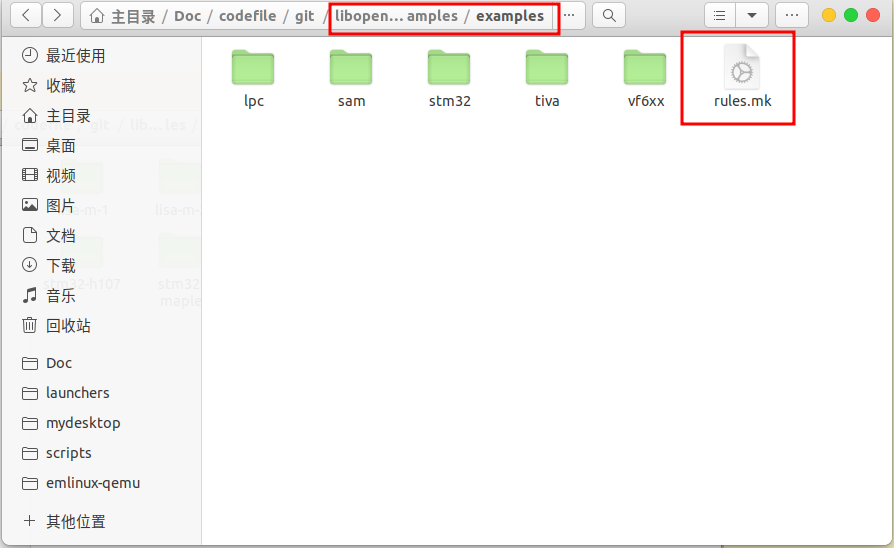
- 复制链接脚本文件(.ld)到MyProject,注意链接脚本通常在 libopencm3 库内,但内容通常是空白模板,需要你根据芯片实际情况手动编写或修改;
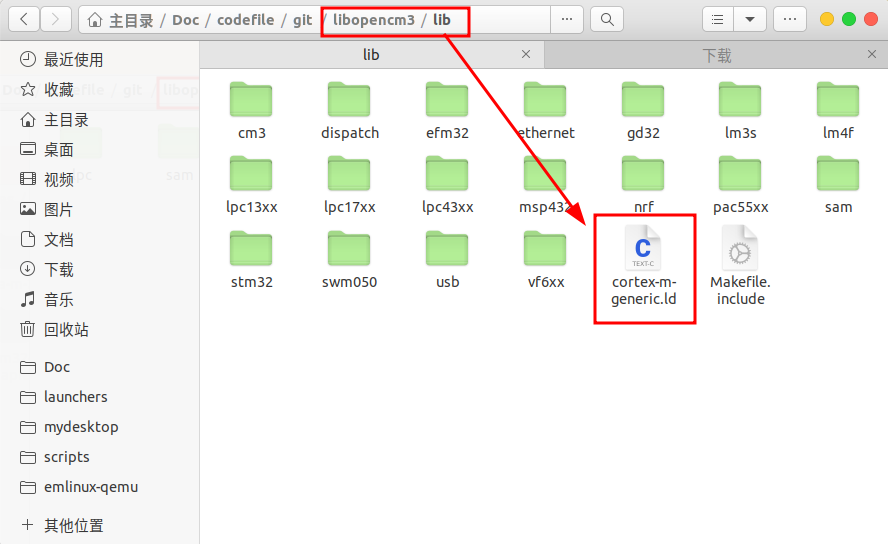
在/* Enforce emmition of the vector table. */这一行之前添加:
1 | MEMORY |
其中,rom 和 ram 分别表示程序存储器和数据存储器的起始地址和大小,根据你的芯片型号进行修改;
配置 Makefile
查看复制出来的 Makefile,修改之后的内容大致如下:
1 | # 指定主目标,最终生成的可执行文件名(对应源码入口) |
配置 Makefile.include
这个文件主要包含对 rules.mk 的引用,通常不需要大幅修改,只需确保路径正确:
1 | include ./rules.mk |
修改 rules.mk
rules.mk 是关键的编译规则文件,下面几个点需要根据你的项目调整:
- 优化选项
建议开发阶段关闭优化,便于调试:
1 | # 关闭优化,避免变量被优化掉 |
- 源文件列表
在这里添加你的所有源代码文件,路径和文件名要准确:
1 | OBJS += $(BINARY).o |
- 库路径
将 libopencm3 的路径改为你本地的相对路径:
1 | LIBPATHS := ../libopencm3 |
最终文件结构示意
1 | project-root/ |
编写代码
在 Src 文件夹下创建 main.c 和 mygpio.c 文件,分别编写你的主程序和 GPIO 操作代码,这一部分可以参考例程,我在此不过多赘述;
编译和生成文件
在 MyProject 目录下执行以下命令,即可编译生成可执行文件:
1 | make |
若要生成不同格式的目标文件,可以使用:
1 | make hex # 生成十六进制文件 |
生成的文件一般在 Src 目录下,并以目标名命名;
调试
在开发流程中,虽然下载程序到芯片是最终目的,但我更倾向于先搭建好调试环境,确保调试能够顺利进行,因此这里先介绍调试配置部分;
J-Link 调试工具准备
我使用的是 Segger 的 J-Link 调试器及其相关软件,使用前需要提前安装官方提供的 J-Link 软件包,确保系统中包含 JLinkGDBServer 等调试工具;J-Link 在稳定性和兼容性上表现非常好,推荐使用;
具体怎么安装在此不做赘述,请自行查阅相关资料;
VSCode Cortex-Debug 插件安装
在 Visual Studio Code 中,安装官方的 Cortex-Debug 插件,这是一个专门为 ARM Cortex-M 系列设计的调试扩展,支持多种调试服务器(如 J-Link、OpenOCD 等);
安装完成后,进入 VSCode 的调试(Debug)界面,点击“创建启动配置”(launch.json),配置内容示例如下:
1 | { |
- executable:填入你的 ELF 文件路径,通常位于 Src 文件夹内;
- device 和 svdFile 需根据具体芯片型号匹配,SVD 文件可以从 GitHub 上的 CMSIS-SVD 仓库 下载,也可以从 Keil 或 OpenOCD 项目中获得;
- armToolchainPath 指向你本地安装的 ARM 工具链目录;
预构建任务配置(preLaunchTask)
调试前自动构建项目非常方便,但我在配置时遇到过困难,后来采用了简单直接的方法;
在 .vscode 文件夹下新建(或修改)tasks.json,内容如下:
1 | { |
这样,在启动调试时,VSCode 会先执行 make clean && make,确保你的代码是最新编译的;如果项目体积大或者编译时间长,平时也可以改为只执行 make,避免重复清理;
注意事项
- 调试流程:通过上述配置,启动调试后,VSCode 会调用 J-Link GDB Server 连接目标设备,加载程序并停留在断点,支持单步、寄存器查看、变量监控等调试功能;
- SVD 文件的重要性:正确的 SVD 文件能极大提升调试体验,方便查看寄存器状态和外设寄存器,建议务必配备正确型号的 SVD 文件;
- 工具链路径:如果你使用的是自己手动安装的 ARM 工具链,记得在配置中填写准确的路径,避免找不到编译器的问题;
固件下载
在调试环境搭建之后,固件下载(烧录)同样是开发流程中不可或缺的一步;如果暂时无法通过 IDE 或调试工具完成自动下载,也可以采用命令行脚本的方式实现烧录;
为什么先说调试再说下载?
实际开发中,我是先搭建好调试环境,能够稳定调试程序后,再完善下载步骤;因此调试优先,下载后续补充;调试成功后,即使暂时无法执行下载操作,也可以调试之后手动断开连接进行程序的烧录,保证开发流程不中断;
编写 J-Link 烧录脚本 flash.sh
创建一个名为 flash.sh 的脚本文件,赋予其执行权限:
1 |
|
- loadfile $1 代表通过参数传入需要烧录的固件文件路径;
- 最后一行启动 J-Link Commander 并执行前面生成的指令脚本;
- 需要根据自己实际的芯片型号(这里以 STM32F103ZE 为例)和调试接口(SWD 或 JTAG)调整参数;
在 Makefile 中添加烧录命令
为了方便使用,可以在 Makefile 中添加一个 upload 目标,集成烧录脚本调用:
1 | upload: all |
- 执行 make upload 会先执行 make all 编译生成目标程序,然后调用 flash.sh 脚本烧录 main.elf;
- 这里示例使用 ELF 格式固件文件,如果你想使用 HEX 文件,也可以,需在 Makefile 中增加 make hex 生成 HEX 文件,并调整脚本中烧录的文件名;
使用脚本处理中间文件
在使用 libopencm3 开发 STM32 时,通过我修改的 Makefile 编译规则会将所有生成的中间文件(如 .o、.elf、.hex 等)和目标文件都放在源代码目录 Src 下面,这样会导致源文件目录显得杂乱不堪,影响阅读和维护;为了解决这个问题,我通过编写自动移动文件的脚本,实现了将生成文件集中存放到一个独立的 build 目录中,从而让源代码目录保持简洁;
手动创建 build 目录
首先,在项目根目录下手动创建一个 build 文件夹,和 Src、Inc 等源码目录平级,用于存放所有编译产生的中间文件和目标文件;
编写移动文件脚本 move.sh
以下是自动将编译产生的文件从 Src 目录递归移动到 build 目录的脚本:
1 |
|
- 该脚本会递归查找 Src 目录下所有常见编译生成的文件,并移动到 build 目录;
- 记得给该脚本执行权限:chmod +x move.sh;
修改 rules.mk 让编译默认生成所有目标格式
找到 rules.mk 文件中大约第 148 行的 all 规则,将其改为:
1 | all: elf bin hex srec list images |
这样做是为了让 Makefile 在默认构建时生成几乎所有格式的二进制文件,方便后续处理;
修改 images 规则调用移动脚本
继续在 rules.mk 中找到生成 .images 文件的命令部分,添加执行移动脚本的命令,变更为:
1 | %.images: %.bin %.hex %.srec %.list %.map |
这样,每当生成 .images 文件时,都会自动调用 move.sh 脚本,把所有中间文件移到 build 文件夹;
修改 clean 规则实现对 build 目录的清理
为了彻底清理所有生成文件,改写 clean 规则为伪目标,并加上对 build 文件夹内文件的强制删除:
1 |
|
- 使用 -rm -f 选项忽略不存在文件的删除错误,保证清理过程顺畅;
- 这样清理命令不仅删除源目录下的中间文件,也清空了 build 目录;
调整下载脚本及 Makefile upload 目标
由于生成文件都移动到了 build 文件夹,下载命令也需要相应调整:
1 | upload: all |
这里示例采用 HEX 文件进行下载,当然也可以改成 ELF 或 BIN,根据自己的需求调整;
更新调试配置中的可执行文件路径
调试器配置文件(如 VSCode 的 launch.json)中,指定的可执行文件路径也要同步修改为:
1 | "executable": "./build/main.elf" |
这样,在调试时,VSCode 会从 build 目录加载最新的可执行文件;
通过以上步骤,我们不仅优化了编译流程,还整理了项目目录结构,使得源代码目录更加简洁,便于维护和阅读;
总结
在本文中,我们详细介绍了如何使用 libopencm3 驱动库进行 STM32 开发,并通过一系列步骤帮助大家搭建了开发环境,配置了交叉编译工具链和项目目录结构,同时也深入探讨了如何高效地进行调试和固件下载;
通过以下几部分内容,你应当能掌握 libopencm3 在 STM32 上的基本使用方法:
- 开发环境准备:首先,我们成功安装了交叉编译工具链 arm-none-eabi-gcc,并配置了 libopencm3 库,确保所有依赖和工具都已正确设置;
- 项目目录结构:为了便于管理和维护项目代码,我们创建了清晰的项目结构,将库和项目代码分开管理,并且在 Makefile 和相关配置文件中做了必要的调整;
- 代码调试:我们展示了如何完成调试环境的配置;特别是 J-Link 调试器和 VSCode 的调试插件,确保了调试过程的高效和顺利;
- 固件下载与烧录:针对固件的下载,我们提供了详细的 J-Link 烧录脚本示例,帮助大家实现通过命令行进行烧录,并将这个过程集成到 Makefile 中,方便在构建过程中直接调用;
- 项目文件管理优化:我们还讨论了如何通过编写自动文件管理脚本,将生成的中间文件和目标文件移至专门的 build 目录中,避免源代码目录杂乱,提高了项目的可维护性;
在整个开发过程中,libopencm3 作为一个轻量级、开源的驱动库,极大地方便了跨平台开发,尤其在 STM32 和其他 ARM Cortex-M 系列芯片之间的移植工作中提供了很大的灵活性;通过与 STM32 官方库对比,libopencm3 提供了更直接和简洁的硬件寄存器操作方式,允许开发者获得更细粒度的硬件控制,并能更好地适应特定的硬件需求;
随着开发的深入,读者可以根据本篇文章提供的基础架构,进一步扩展和优化自己的项目;比如,在未来的开发过程中,可以根据实际需求选择合适的硬件外设,并逐步加入复杂的功能模块,同时确保调试和烧录过程的顺畅;此外,libopencm3 作为开源项目,也鼓励大家参与到库的贡献和扩展中去;
通过掌握这些基础技巧,相信你可以在 STM32 项目的开发中更加得心应手,同时也能够为今后的跨平台开发积累宝贵经验;